| |
|
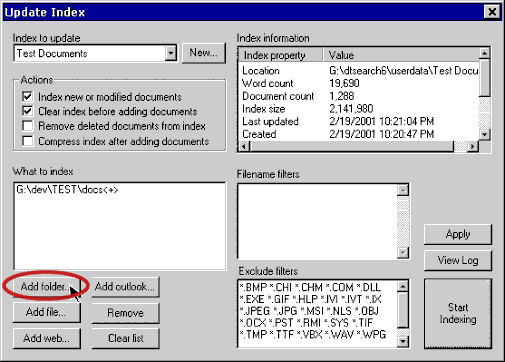
dtSearch™ WebdtSearch™ Web – the easy, out-of-the-box Web solution •Just a few clicks adds a dozen instant indexed text search options to your site. •Displays HTML and PDF with highlighted hits, keeping all embedded links and images intact. •Uses built-in file converters to convert other file types — word processor, database, spreadsheet, ZIP, Unicode, etc. — to HTML for display with highlighted hits. < •Provides multiple hit and file navigation options. •For an online demo of dtSearch™ Web, including HTML, PDF and XML, demos, click here. How dtSearch™ Works on the Web dtSearch™ Web uses an index that it builds to search instantly through gigabytes of text. Just select directories to index — dtSearch™ automatically recognizes and supports all popular file formats, and never alters original files. Requirements dtSearch™ Web requires IIS 4 or 5 (included with Windows NT/2000) to install. dtSearch™ Web operates through the dtSearch™ Desktop user interface to make indexing really easy. Just select "Add folders" in the dialog box below, and dtSearch™ will do the rest. Once dtSearch™ has built an index, it can automatically update it using the Windows Task Scheduler to reflect additions, deletions and modifications to your document collection.
Web Setup With a few mouse clicks, dtSearch™ Web Setup lets you install dtSearch™ Web. You can designate multiple indexes to search on your site, and automatically generate a search form.
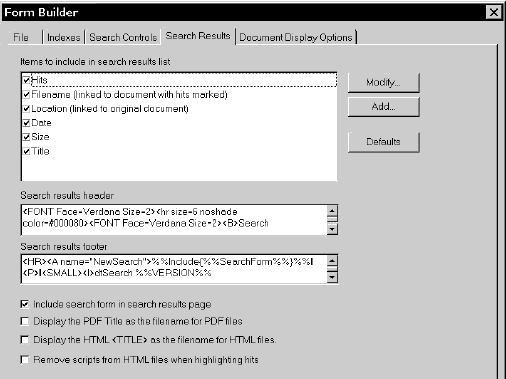
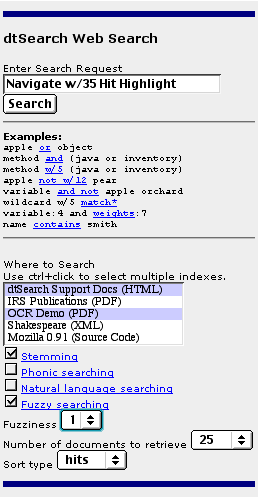
The form builder provides numerous optional ways to customize the contents of search results, document display, and the search form itself. (You can also use an HTML editor such as Microsoft FrontPage to edit the resulting search form.) Searching The form builder will automatically install the search form on your Web site, so visitors can instantly search, including over a dozen text search options. A sample modified follows:
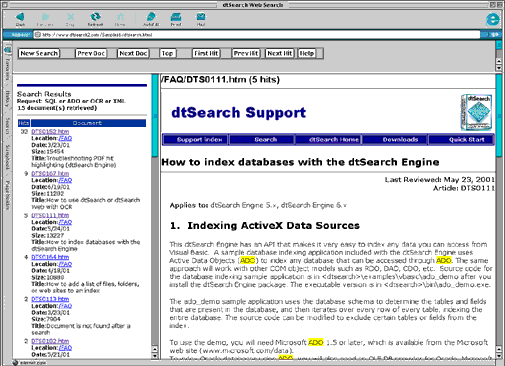
After a search, dtSearch™ Web will display retrieved files with hit highlighting, and all links and images intact. The result looks just like the original HTML or PDF page, but with highlighted hits. HTML links also remain in the document display and fully functional. Buttons like "next hit," "previous document," "next document," etc., also let you navigate through your hits and documents.
HTML file retrieved by dtSearch™ Web. The buttons on the adobe reader tool bar navigate hits in the PDF files. To avoid delays in displaying long Web-based PDF files through the combined browser / Adobe Reader interface, dtSearch™ will first download only the page with the "hit" highlighted. dtSearch™ will then download additional pages as the user browses through the document. PDF file retrieved by dtSearch™ Web. For XML, dtSearch™ can perform indexed searches using the full range of dtSearch™ features across an entire XML database, or limited to a highly specific combination of fields or sub-fields. dtSearch™ Web nested-field search of Shakespeare XML database. For other file types, dtSearch™ uses built-in HTML file converters to convert non-Web-ready formats such as word processor, database, spreadsheet, ZIP, Unicode, etc., to HTML for display with highlighted hits. Canadian on-line dtSearch™ users - try these search engines for yourself Agrifinance (search for "farm") Technical Note The dtSearch™ Text Retrieval Engine includes sample source code to dtSearch™ Web in both ASP and ISAPI versions, as well as an extensive programmable API supporting multiple programming languages.
•For a "Web Based Data Management: HTML vs. PDF vs. XML" article, click here. •For "The New Paper Trail: Alternative Information Distribution" article, click here. RCC Consulting is a division of R-4 Investments Inc.
|