| |
|
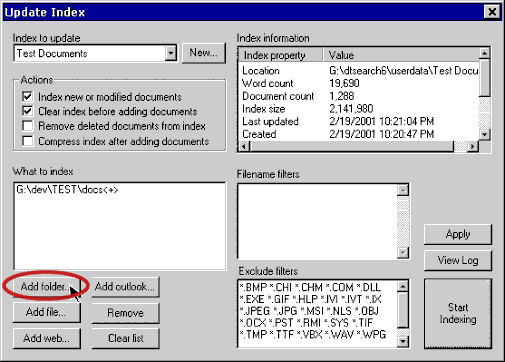
dtSearch™ DesktopOnce dtSearch™ has built an index, search speed is usually less than a second, even through multiple gigabytes of text. dtSearch™ automatically recognizes and supports word processor, database, spreadsheet, email, PDF, HTML, ZIP, XML, Unicode files and more. After a text search, dtSearch™ will display all retrieved files with highlighted hits as well as (for HTML and PDF) images and links intact. dtSearch™ is able to search through gigabytes of text in a second because it builds an index that stores the location of words in files. dtSearch™ automatically recognizes and supports all popular file formats, and never alters your original files. Once dtSearch™ has built an index, search speed is usually less than a second, even through multiple gigabytes of text. Since you may sometimes want to search files that dtSearch™ has not indexed, dtSearch™ also does unindexed as well as "combination" searches. Indexing is easy — just select "Add folders" in the dialog box below, and dtSearch™ will do the rest.
Once dtSearch™ has built an index, it can automatically update it using the Windows Task Scheduler to reflect additions, deletions and modifications to your document collection. dtSearch™ has over two dozen indexed and unindexed text search options. Features to assist in search formation include: •a scrolling word list, providing instant feedback as you type in a search. •a look-up word option, showing the effect on words retrieved with fuzzy, phonic, stemming or wild card searching activated. •a search history option, for displaying and reusing previous search requests. •a browse thesaurus option, for browsing the built-in thesaurus and selectively including words. After a search, dtSearch™ will display a customizable list of all files retrieved in a search request. Simply click to sort (or resort) search results by "relevancy," name, date, or fields. A second window will display the currently selected document. Some things you can do following a search: •Browse all retrieved files (word processor, database, spreadsheet, email, Unicode, etc.) with Unicode, etc.) with highlighted hits. •Browse HTML and PDF with highlighted hits as well as embedded links and images intact. •Automatically un-ZIP and display files in a ZIP archive. •Use multiple hit and file navigation options like "next hit," "previous hit" and "next document" to browse retrieved files. •Do a second-level text search in a retrieved file. •See an executive summary of your search results showing hits in context. •Cut and paste text; export search results to another application. •Launch a file in its native application.
dtSearch™ Desktop displays an HTML file retrieved by dtSearch™ Spider A built-in image viewer can also display popular graphics formats (TIF, GIF, PCX, BMP, JPG, EPS, etc.). Just click to switch from the text of a file (myfile.doc) to images associated with that file (myfile1.tif, myfile2.tif, myfile3.tif). The image viewer also supports features such as zoom, flip and invert. •dtSearch™ Spider for searching across the Web from within dtSearch™ Desktop. •dtSearch™ Network for network use. •FindPlus® Distributed Searching, for searching remote enterprise
servers. RCC Consulting is a division of R-4 Investments Inc.
|